Improve this architecture

Someone asked how I would improve the architecture of the Rev1 image in about 10 minutes with a one-week delivery deadline for the solution. Sounds simple enough right? The first thing to clarify was the use case of such an architecture; how many people are using it and why. Okay so there are about six thousand tenants times multiple accounts accessing this architecture throughout the day, there is burst activity in the early hours and sporadic access during evenings, but this workload mainly follows the sun for a single region and is not globally available. We don't know why they are using this or what this service is actually doing.
The Diagram (Rev1)
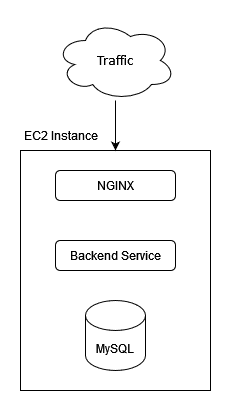
Initial thoughts
Rev1 is not: scalable, highly-available nor reliable. It also invalidates the single-responsibility principle. What do I mean by that and why?
- Not Scalable: There is a single EC2 instance with no auto-scaling group (ASG) present to handle an increase or decrease in service requests
- Not highly available: There is no failover or recovery of this instance should it go down.
- Not reliable: There is a maximum amount of requests that this instance can handle at any given time, this could cause traffic to be bunched up at the NGINX instance, there could also be access problems at the data layer due to a maximum amount of read/write worker threads available compared to maximum number of pooled requests available from NGINX.
- Invalidates SRP: This instance is performing three separate roles, all are dependent on each other and should one card fall, the whole stack of cards comes crumbling down.
- Out of scope: The inner workings of the Backend service are out of scope as this is implementation detail on a layer separate from the high-level architecture of such a solution. (See C4 model for Architecture visualisation)
Two potential solutions
The simple answer I might give as a Senior Manager (Rev2):
This is a time critical ask, so in a situation where the team is directly asking me for a potential solution id suggest:
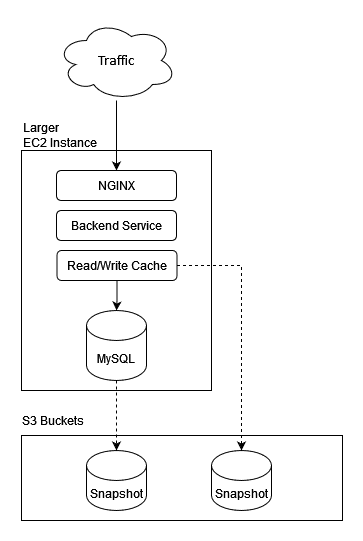
- Snapshot MySQL immediately
- Create a bigger EC2 instance
- Snapshot the MySQL database into S3 every hour to have a -1 Hour RPO and leave it there giving you a +1 Hour RTO after disaster to recover the data-layer..
- Deploy a read-write caching solution (e.g. Redis) between the Backend and Data-Layer to mitigate failures in the data layer.
- Re-deploy your Backend service and NGINX instance. Optional: Put this instance into an ASG, place MySQL into a separate EC2 instance so ASG scaling doesn't duplicate MySQL instances.
How long do you think this would take with a team of 4 engineers? reply in the comments on my LinkedIn post.
The answer I would give as an Engineering Lead (Rev3):
We have a week and a handful of engineers to get this done, this is priority and whatever we build we need to be happy that the solution will stand on its own two feet, here are some action items:
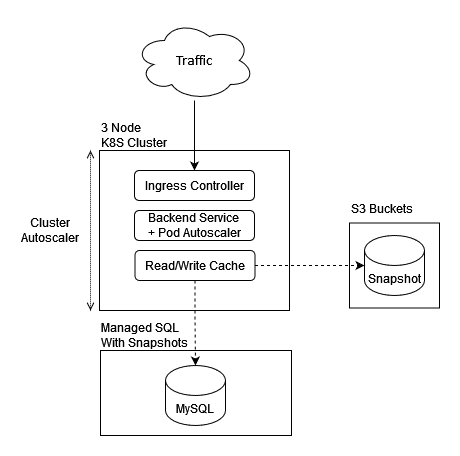
- Snapshot MySQL immediately
- Create a managed K8S cluster
- Dockerise the Backend backend
- Create an NGINX ingress controller
- Update DNS
- Push our containers to any hosted registry
- Create a manual deployment of the backend with secrets to connect to a managed MySQL instance somewhere in the provider.
- Snapshot MySQL again and run a restore from snapshot of the data-layer to our hosted MySQL instance. Done.
How long do you think this would take with a team of 4 engineers? reply in the comments on my LinkedIn post.
So what does this look like?
Rev2 Diagram
Highlighting my approach as a Senior Manager
Rev3 Diagram
Highlighting my approach as an Engineering Lead
Final thoughts
It goes without saying that Rev3 is more complex to implement, both in required knowledge of the team and initial deployment, however; with the correct planning it can be achieved relatively quickly.
Is it my preferred solution? Maybe - depending on cost, team size etc.
I'd estimate the implementation of Rev3 would take four mid-level engineers with some Kubernetes experience to implement this solution for a single environment before the required delivery date.
Notes - Outside of scope for 1 week delivery
I'd speak to the cloud provider to secure a commited use discount for all worker nodes that we're using to bring the cost down to something comparable to spot instances and hibernate any on-demand instances.
Stay tuned & follow
Stay tuned and follow me for my next post on architecture where we discuss how to get the most out of a single Kubernetes control-plane, it's going to be an interesting one.